



In this blog we will learn about querying in Series, Iterating through series elements, merging 2 series objects together and and importance of thinking about parallelization when engaging with Pandas in general.
Before moving ahead, for the purpose of demonstration I would first like to create a Series object.
import pandas as pd
import numpy as np
#Making Series Object From a Dictionary
sampleDictionary={"Alia":"Maths","Ash":"Chemistry","Nick":"Computer"}
newConstruct=pd.Series(sampleDictionary)
print(newConstruct)
The corresponding Series Object will look something like this.

Querying in a Series Object
A Pandas Series can be queried either by the index numbers(The number pandas assign to series data starting from zero) or the labels(indexes we assign to series data at the time of creation). If we are querying through series which has no label, then index numbers and the labels are effectively the same values.
To query by index number, starting at zero, use the iloc attribute.
To query by the label, you can use the loc attribute.
The syntax for iloc and loc is as follows.
<Name Of The Series>.loc["Index Label"]
<Name Of The Series>.iloc["Index Number"]
Lets see a few examples for better understanding.
#iloc implementation. Example 1.
newConstruct.iloc[2]
The output is as follows:
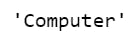
#iloc implementation. Example 2.
newConstruct.iloc[0]
The output is as follows:
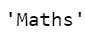
#loc implementation. Example 1.
newConstruct.loc["Ash"]
The output is as follows:
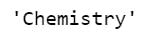
#loc implementation. Example 2.
newConstruct.loc["Alia"]
The output is as follows:
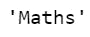
Off-course there will be a sense of confusion between iloc and loc for querying a Series. One way to remember is loc for label. Alternatively, iloc for index label.
Keep in mind that iloc and loc are not methods, they are attributes. So you don't use parentheses to query them, but square brackets instead.
Pandas tries to make our code a bit more readable and provides a sort of smart syntax using the indexing operator directly on the series itself. For instance, if you pass in an integer parameter, the indexing operator will behave as if you want it to query via the iloc attribute
Lets understand via example.
#iloc implementation using indexing operator
newConstruct[2]
The output is as follows:
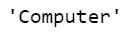
Similarly, If we pass in an label alongside the series and index operator, it will query as if you wanted to use the label based loc attribute.
Lets see an example.
#implementing loc via index operator.
newConstruct["Ash"]
The output will be as follows:
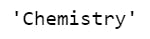
So what happens if our labels are a integers? This is a bit complicated and Pandas can't determine automatically whether you're intending to query by index number or by labels. So you need to be careful when using the indexing operator alongside Series. The safer option is to be more explicit and use the iloc or loc attributes directly.
Lets first construct this kind of Series.
#Integer labels based Series.
sampleDictionary={99:"House",100:"Water",98:"Food"}
newConstruct=pd.Series(sampleDictionary)
print(newConstruct)
The Series looks something like this:

Lets now see what happens when we implement indexing operator here directly.
newConstruct[0]
Output is as follows:
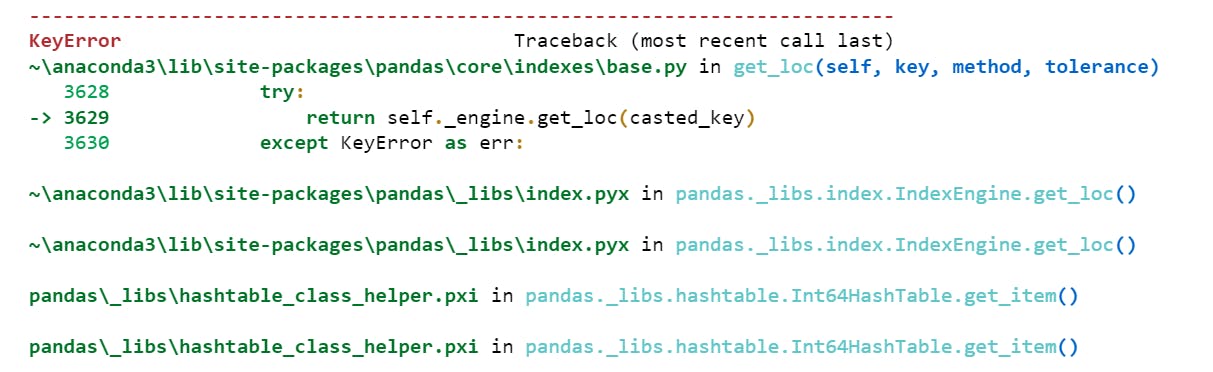
Yeah, so an error is generated. Hence explicitly use iloc and loc in case we have integer labels.
Working With Queried Data: Iteration and Broadcasting
Now we know how to extract data out of Series Data structure. Lets now see a few example where we can use this data and perform operations.
Example1: Given we have marks scored by a student in a series. Our task is to find the average marks scored by the student.
#Array based Series object.
marks=[90,74,100,45,67]
marksSeries=pd.Series(marks)
totalMark=0
totalSubject=0
for i in marksSeries:
totalMark=totalMark+i
totalSubject=totalSubject+1
average=totalMark/totalSubject
print(average)
The output is as follows:
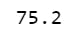
Lets solve this question using another method, the sum method of NumPy.
marks=[90,74,100,45,67]
lenght=len(marks)
totalMarks=np.sum(marksSeries)
average=totalMarks/lenght
print(average)
The output is as follows:

See both the codes above do the same thing. But we need to find who is faster.
Here, we're actually going to use what's called a cellular magic function. The function we're going to use is called timeit. This function will run our code a few times to determine, on average, how long it takes.
The general syntax to be used is
%%timeit -n < Number >
< code >
The number above will define how many times the magic function variable has to work\run to find the average.
Lets apply it on our previous codes and see how it works.
#For code 1
%%timeit -n 100
totalMark=0
totalSubject=0
for i in marks:
totalMark=totalMark+i
totalSubject=totalSubject+1
average=totalMark/totalSubject
average
The output is as follows:
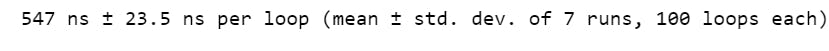
#For code 2
%%timeit -n 100
marks=[90,74,100,45,67]
lenght=len(marks)
totalMarks=np.sum(marksSeries)
average=totalMarks/lenght
print(average)
The output is as follows:

As we can observe, the first code is faster than second one and hence we should move on with it.
Broadcasting
Now the next thing we can discuss about is Broadcasting. With broadcasting, you can apply an operation to every value in the series, changing the series. For instance, if we wanted to increase every marks scored in each subject by 2, we could do so quickly using the += operator directly on the Series object.
Let see that.
#Creating Series Object.
marks=[90,74,100,45,67]
marksSeries=pd.Series(marks)
#Broadcasting(Adding 2 to each element)
marksSeries=marksSeries+2
marksSeries
Initial

After Changes

As observable changes are appearing. The procedural way of doing this would be to iterate through all of the items in the series and increase the values directly. Pandas does support iterating through a series much like a dictionary, allowing you to unpack values easily. But for that we need to use a special method called iteritems(). Let see the syntax.
for < Index Variable >,< DataVariable > in < Series >.iteritems():
<Series>.loc[Index Variable]=DataVariable<Operator><Operand>
The following code is as follows:
#Creating A Series Object.
marksDictionary={"English":90,"Math":74,"Science":100,"Hindi":45,"Computer":67}
marksSeries=pd.Series(marksDictionary)
#Broadcasting(Adding 2 to each element)
for subject,marks in marksSeries.iteritems():
marksSeries.loc[subject]=value+2
The change in series can be as follows:
Initial

After Changes

Another aspect we can look into in the above two codes is to see which is faster. Lets run the timeit cellular function on these codes again.
#Estimation For First Method.
%%timeit -n 100
#Creating Series Object.
marks=[90,74,100,45,67]
marksSeries=pd.Series(marks)
#Broadcasting(Adding 2 to each element)
marksSeries=marksSeries+2
marksSeries
The output will be as follows:

For the second code, average time is as follows
#Estimation For Second Method
%%timeit -n 100
#Creating A Series Object.
marksDictionary={"English":90,"Math":74,"Science":100,"Hindi":45,"Computer":67}
marksSeries=pd.Series(marksDictionary)
#Broadcasting(Adding 2 to each element)
for subject,marks in marksSeries.iteritems():
marksSeries.loc[subject]=marks+2
The output is as follows:
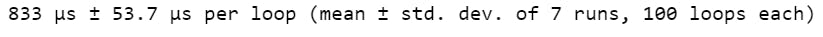
Clearly the first code is faster than the second.
Well that would be the end of this blog. Here I have tried my best to go in details about how can you work around Pandas Series. We have discussed, How to access Series data via loc, iloc and indexing operator?, How to iterate through a Series?, What is Broadcasting and the methods to perform broadcasting?. All this would conclude the end of this blog.
This blog is a Part 2 two Part Blog series on Pandas Series Object.
If you like the content and if it really helped you out, do consider subscribing my blog.
You can also connect with me on Linkedin and Twitter, should you wish to do so.